BERT는 Transformer 이후에 나온 모델이다.
Transformer에서 Encoder 부분을 사용한 모델로 BERT 이후에 BERT 기반으로 개선하고 발전시킨 연구들이 많이 등장했다.
- 논문: https://arxiv.org/abs/1810.04805
- github: GitHub - google-research/bert: TensorFlow code and pre-trained models for BERT
BERT(Bidirectional Encoder Representations from Transformers)
앞에서도 말했듯이 BERT는 Transformer의 Encoder와 같은 구조이다.
Transformer 설명은 [논문] Attention Is All You Need | Transformer에서 확인할 수 있다.
BERT에서 제안한 것은 MLM(Masked LM)과 NSP(Next Sentence Prediction)이다.
MLM과 NSP로 Pre-train을 하고, 다양한 NLP task에 대해서 fine-tuning을 한다.

모델 구조

BERT의 구조는 위의 Transformer 구조 그림에서 빨간 박스에 해당하는 부분과 같다.
Embedding 값이 Encoders를 통과하고 마지막 레이어에서 각 토큰들의 값을 구할 수 있다.
BERT는 크기에 따라 base와 large가 있다.
초기 Transformer와 비교하면 더 큰 모델이다.
| # of layers | hidden size | # of self-attention heads | |
|---|---|---|---|
| BERT_base | 12 | 768 | 12 |
| BERT_large | 24 | 1024 | 16 |
| Transformer | 6 | 512 | 8 |
Input/Output Representations
BERT의 Input은 Transformer의 Input과 비슷한데 Token Embeddings과 Position Embeddings 외에 Segment Embeddings이 있다.
먼저 토큰들을 분리하는데 이 때 WordPiece를 사용하여 30,000개의 token vocabulary를 만든다.
그리고 항상 첫번째 토큰으로 [CLS] 토큰을 추가하는데, 이는 분류 task에서 사용된다.
[SEP] 토큰은 문장과 문장 사이에 추가되는 토큰으로 문장을 구분한다.
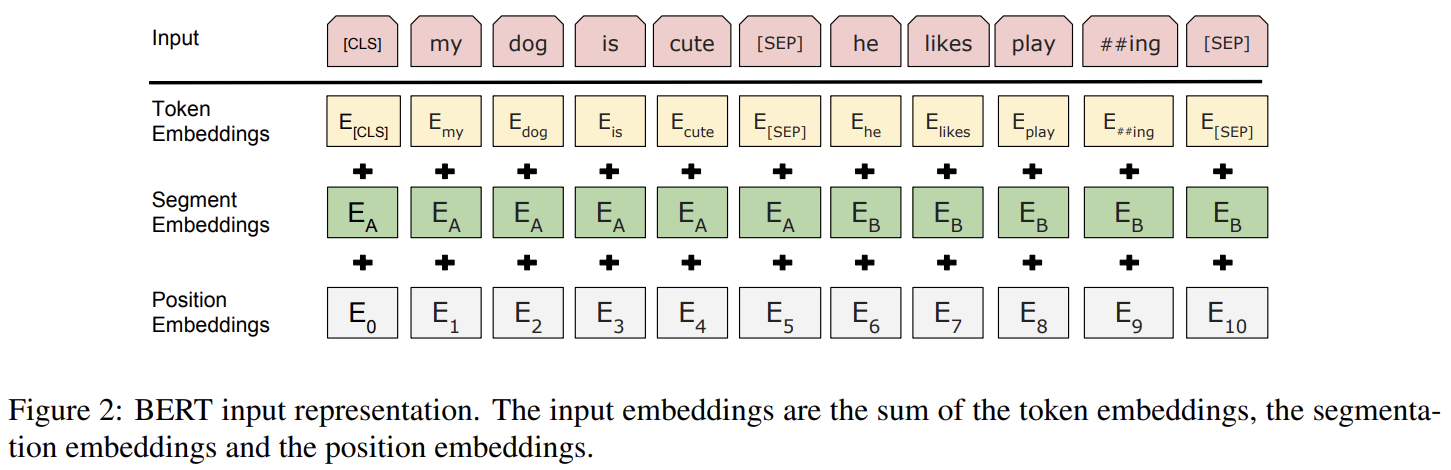
- Token Embeddings: Token에 대해서 정수 인코딩한 뒤에 Embedding Layer를 통과한 값
- Position Emeddings: Token의 위치 정보를 나타내는 값
- Segment Embeddings: 문장과 문장을 구분하는 값으로 첫번째 문장의 토큰들은 0, 두번째 문장의 토큰들은 1 값을 가짐
Pre-training BERT
위에서 언급했듯이 BERT는 MLM과 NSP 학습을 통해 pre-train을 한다.
MLM(Masked LM)
MLM은 토큰의 일부를 [MASK] 토큰으로 변경하여 [MASK] 토큰에 해당하는 원래 토큰은 무엇인지 맞추는 학습 방법이다.
논문에서는 이를 통해 양방향 학습을 할 수 있다고 한다.
모든 토큰에 대해서 [MASK] 토큰으로 변경하지 않는 이유는 fine-tuning할 때는 [MASK] 토큰이 사용되지 않기 때문이다.
따라서 전체 토큰 중에 12%만 [MASK] 토큰으로 변경하고, 1.5%는 랜덤으로 토큰을 변경하고, 또 다른 1.5%는 변경하지 않고 예측하도록 학습한다.

위의 그림과 같이 해당 토큰들의 마지막 레이어 output 값을 가지고 분류하며 학습하게 된다.
NSP(Next Sentence Prediction)
NSP는 QA(Question Answering)과 NLI(Natural Language Inference) task을 위한 학습이라고 볼 수 있다.
두개의 문장을 선택하여 두 문장의 순서가 올바른지를 학습하는데, 전체 중 50%는 올바른 순서의 두 문장을 선택하고, 나머지 50%는 랜덤으로 선택한다.

두 문장의 순서가 올바른지는 위의 그림처럼 [CLS] 토큰 값을 이용하여 예측한다.
Fine-tuning BERT

task에 따라서 fine-tuning 학습 방법이 조금 다르다.
(a), (b)와 같이 분류 문제에서는 [CLS] 토큰의 값으로 분류 문제에 대해서 학습을 하게 된다.
(c)와 같이 QA 문제는 두번째 문장에 해당하는 paragraph 토큰들의 값으로 정답의 범위를 학습한다.
(d)와 같이 태깅 문제에서는 [CLS] 토큰을 제외한 모든 토큰들의 값으로 태그를 학습한다.
BERT fine-tuning은 GLUE, SQuAD v1.1, SQuAD v2.0, SWAG 데이터셋을 사용하였고, 성능 평가 결과 11개의 task에서 SOTA 달성했다.
Reference
'Study' 카테고리의 다른 글
| Language Model 관련 연구 리스트(2017~2020) (0) | 2022.01.24 |
|---|---|
| Passage Retrieval 관련 연구 (0) | 2022.01.22 |
| [논문] Attention Is All You Need | Transformer (0) | 2022.01.10 |
| 추천 시스템 성능 평가 지표(Precision@k, Recall@k, Hit@k, MAP, MRR, nDCG) (0) | 2022.01.09 |
| 회귀 모델 성능 평가 지표(MAE, MSE, RMSE, MAPE 등) (1) | 2022.01.07 |
