기존 NLP에서는 RNN 기반의 모델들이 주로 사용되었다.
2017년 구글이 Attention is all you need 논문을 발표하면서 Transformer 모델이 등장했고, 현재 NLP에서는 Transformer 기반으로 모델들이 발전되고 있다.
본 게시글은 Attention is all you need 논문과 여러 블로그의 글을 읽고 정리한 글이다.
Transformer
Transformer는 기계 번역 모델로 공개되었으나 다양한 NLP task에 활용된다.
기존 기계 번역 모델과의 차이점은 아래와 같다.
- RNN, LSTM 등을 사용하지 않고 Attention만으로 구현됨
- 입력을 순차적으로 받지 않기 때문에 임베딩 벡터에 단어의 순서 정보를 추가함
모델 구조
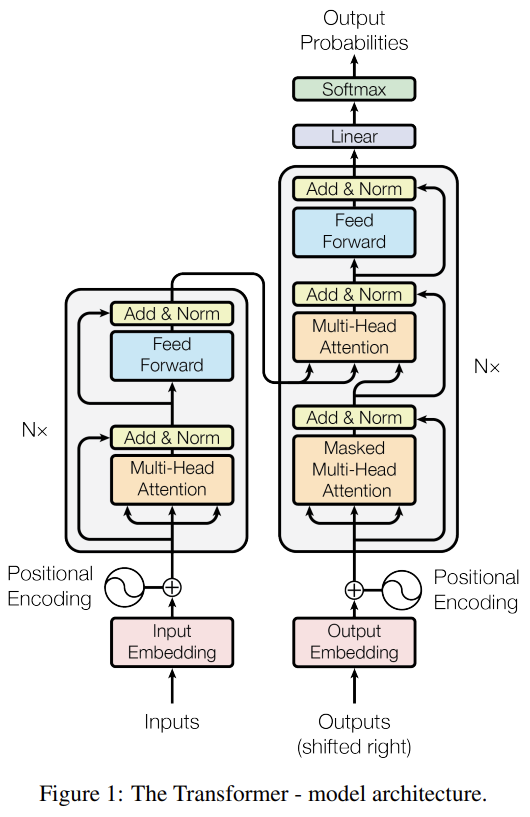
Transformer는 Sequence-to-Sequence 구조로 Encoder와 Decoder가 있다.
먼저 Encoder는 3가지 레이어로 구성된다.
Encoder
- Multi-Head Attention
- Feed Forward
- Add & Norm
이러한 Encoder 레이어를 총 N개 쌓는데 이를 Encoders라고 부른다.
Decoder는 4가지 레이어로 구성된다.
Decoder
- Masked Multi-Head Attention
- Multi-Head Attention
- Feed Forward
- Add & Norm
Decoder 역시 총 N개의 Decoder 레이어를 쌓고 이를 Decoders라고 부른다.
아래에서 Encoder와 Decoder에 대해서 좀 더 자세하게 설명한다.
Encoder
Encoders는 문장에서 어떤 단어가 더 중요한지를 구하는 부분이다.
위에서 Encoder는 총 3가지 레이어로 구성된다고 하였다.
3가지 레이어를 살펴보기 전에 input에 대해서 먼저 살펴본다.
Input
Figure 1를 보면 Inputs가 Input Embedding 레이어의 입력으로 들어가고, Input Embedding의 출력이 Positional Encoding과 더해진다.
Inputs는 입력 문장을 정수 인코딩한 값이고, Input Embedding 레이어는 임의의 가중치로 초기화된 레이어 또는 사전 학습된 것을 가져와서 사용할 수 있다.
Input Embedding 레이어의 출력은 입력 문장의 단어 벡터가 된다.
Positional Encoding은 아래 수식으로 계산된다.
$$
PE_{(pos,2i)} = sin(pos / 10000^{2i/d_{model}})
$$
$$
PE_{(pos,2i+1)} = cos(pos / 10000^{2i/d_{model}})
$$
- $pos$: 입력 문장에서의 단어 벡터
- $i$: 단어 벡터 내의 차원의 인덱스
- $d_{model}$: Transformer의 모든 층의 출력 차원(=512)
예시를 들어보면 아래와 같다.
- 문장: I am student
- Inputs(문장을 정수 인코딩한 값, Input Embedding의 입력): [12, 24, 33, 47]
- Input Embedding의 출력: ['I'를 표현하는 벡터, 'am'을 표현하는 벡터, 'a'를 표현하는 벡터, 'student'를 표현하는 벡터]
- Positional Encoding: ['I'의 위치를 표현하는 벡터, 'am'의 위치를 표현하는 벡터, 'a'의 위치를 표현하는 벡터, 'student'의 위치를 표현하는 벡터]
최종적으로 Input Embedding의 출력과 Positional Encoding을 더한 결과값이 첫번째 Encoder의 입력이 된다.
Attention Mechanism
Transfomer는 Attention으로 구현된 모델이기 때문에 Attention Mechanism에 대한 이해가 필요하다.
Attention Mechanism은 컴퓨터 비전 분야에서 먼저 사용되었는데, NLP 분야에서는 기존 번역 모델에서 입력 문장이 길어지면 번역 품질이 떨어지는 현상을 개선하기 위한 대안으로 사용되기 시작되었다.
Attention Mechanism을 사용하면 디코더에서 출력 단어를 예측하는 매 시점마다 인코더에서의 전체 입력 문장을 다시 한 번 참고를 하는데, 이 때 해당 시점에서 예측해야 할 단어와 연관이 있는 입력 단어 부분을 좀 더 집중해서 볼 수 있게 된다.
$$
Attention(Q, K, V) = Attention \ Score = 단어와 \ 단어 \ 사이의 \ 상관관계를 \ 나타내는 \ 가중치
$$
해당 시점에서 예측해야 할 단어와 연관이 있는 입력 단어 정보가 Attention Score이다.
Attention Score를 구하는 함수는 여러가지가 있는데 Transformer는 Scaled dot-product Attention을 사용한다.
Scaled dot-product Attention
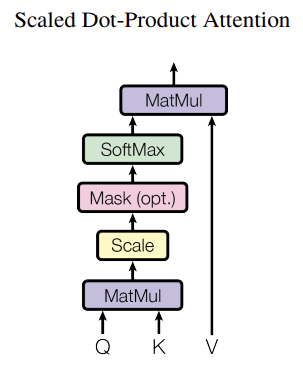
보다시피 Attention Score를 구하기 위해서는 Q(Query), K(Key), V(Value)가 필요하다.
- Q(Query): 영향을 받는 단어로 단어 벡터와 Q를 구하기 위한 가중치를 곱하여 구함
- K(Key): 영향을 주는 단어로 단어 벡터와 K를 구하기 위한 가중치를 곱하여 구함
- V(Value): 영향에 대한 가중치로 단어 벡터와 V를 구하기 위한 가중치를 곱하여 구함
수식은 아래와 같다.
$$
Attention(Q,K,V) = softmax(\frac{QK^{T}}{\sqrt{d_{k}}})V
$$
먼저 Q(Query)와 K(Key)를 곱하고 $\sqrt{d_{k}}$ 로 나눈 뒤 SoftMax(0~1 사이의 값으로 변환, 합이 1이 됨)를 계산하고, 결과값을 V(Value)와 곱하면 Attention Score를 구할 수 있다.
Multi-Head Attention
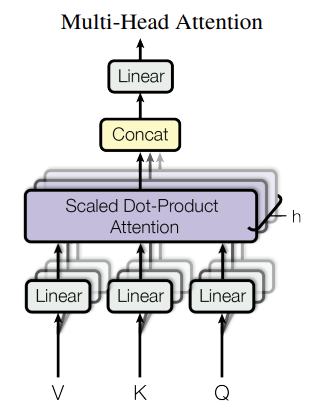
Multi-Head Attention은 여러 개의 Scaled dot-product Attention 레이어를 병렬로 처리하는 것을 말한다.
이 때 Scaled dot-product Attention 레이어는 각각 다른 임의의 가중치(Q, K, V를 구하기 위한 가중치)로 초기화하는데 이는 다른 시각으로 정보를 수집하기 위해서이다.
수식은 아래와 같다.
$$
MultiHead(Q,K,V) = Concat(head_{1}, ..., head_{h})W^{O} \
where \ head_{i} = Attention(QW_{i}^{Q}, KW_{i}^{K}, VW_{i}^{V})
$$
Feed Forward
Position-wise FFNN 이라고도 하는데 일반적으로 알고있는 fully connected feed-forward network라고 보면 될 것 같다.
두 개의 Linear 레이어로 구성되며, 활성화 함수로는 ReLU를 사용한다.
수식은 아래와 같다.
$$
FFN(x) = max(0, xW_{1} + b_{1})W_{2} + b_{2}
$$
- $x$: Multi-Head Attention 레이어 출력이 입력으로 들어간 Add & Norm 레이어의 출력
Feed Forwar 레이어의 출력이 다음 Encoder의 입력이 된다.
Add & Norm
Add는 잔차 연결(Residual Connection)을 말하고, Norm은 층 정규화(Layer Normalization)을 말한다.
Encoder 안에서 Multi-Head Attention 레이어와 Feed Forward 레이어의 위에 위치하는데 Decoder에서도 마찬가지이다.
잔차 연결(Residual Connection)
잔차 연결은 입력값과 출력값을 더하는 것을 말한다.
수식은 아래와 같다.
$$
H(x) = x + F(x)
$$
Multi-Head Attention 레이어를 기준으로 예를 들면 $x$와 $F(x)$는 아래와 같다.
- $x$ : Multi-Head Attention의 입력값
- $F(x)$: Multi-Head Attention 출력값
- $H(x)$: Feed Forward의 입력값
층 정규화(Layer Normalization)
층 정규화는 각 행(단어)의 평균과 분산을 구하여 정규화하는 것을 말한다.
수식은 아래와 같다.
$$
ln_{i} = LayerNorm(x_{i})
$$
$$
\hat{x}_{i,k} = \frac{x_{i,k} - \mu_{i}}{\sqrt{\sigma_{i}^{2} + \varepsilon }}
$$
$$
ln_{i} = \gamma \hat{x}_{i} + \beta = LayerNorm(x_{i})
$$
- $i$ : 행
- $k$ : $x_{i}$의 각 차원 인덱스
$\gamma$와 $\beta$는 각각 1과 0으로 초기화 되어있으며 학습 과정에서 업데이트된다.
잔차 연결 후 수행한다.
Decoder
Decoders는 Encoders를 통해 구한 문장에서 어떤 단어가 중요한지에 대한 정보와 현재 단어를 통해 다음 단어를 예측하도록 학습해야한다.
따라서 학습을 할 때는 전체 문장이 입력으로 들어가지만, 예측을 할 때는 단어가 하나씩 입력이 된다.
위에서 Decoder는 4가지 레이어로 구성된다고 했다.
여기서 Feed Forward 레이어와 Add & Norm 레이어는 Encoder에서 설명한 것과 같다.
따라서 Feed Forward 레이어와 Add & Norm 레이어를 제외한 나머지 2가지 레이어에 대해서 설명한다.
Masked Multi-Head Attention
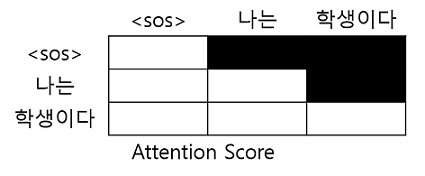
Decoder는 현재 시점 단어를 가지고 다음 단어를 예측하는 부분이라고 하였다.
하지만 Transformer는 단어가 순차적으로 입력되지 않고 한꺼번에 입력되기 때문에 현재 시점 이전의 단어들만 참고할 수 있도록 해야한다.
따라서 현재 시점 이후의 단어들을 마스킹을 해야하는데 이 과정은 Attention Score를 구한 다음에 이루어진다.
예를 들어 입력 문장이 ' 나는 학생이다' 이고, 현재 시점의 단어가 '나는'이라면 '학생이다'에 대한 attention은 0이 된다.
Multi-Head Attention
Transformer의 Decoder는 현재 시점 단어와 Encoder의 출력을 가지고 다음 단어를 예측하도록 학습한다고 했다.
Encoder의 출력은 Attention을 계산할 때 K(Key)와 V(Value)로 사용된다.
이 레이어는 Encoder의 Multi-Head Attention 레이어와 같은 방식으로 Attention Score를 계산하지만, 앞에서 말했듯이 K(Key), V(Value)가 다르다.
Encoder의 Multi-Head Attention
- Query = Key = Value
- Encoder의 입력 문장의 단어들로 구성됨
Decoder의 Masked Multi-Head Attention
- Query = Key = Value
- Decoder의 입력 문장의 단어들로 구성됨
Decoder의 Multi-Head Attention
- Query: Decoder의 입력 문장의 단어들로 구성
- Key = Value: Encoder의 입력 문장의 단어들로 구성(Encoder의 출력)
Encoder와 마찬가지로 Decoder도 각 레이어의 계산이 끝나면 Add & Norm 레이어를 거치고, Feed Forward 레이어의 출력이 다음 Decoder의 입력으로 들어간다.
그리고 모든 Decoder의 계산이 끝나고 마지막 출력값은 Linear 레이어와 Softmax 레이어를 거쳐 다음 단어를 예측하게 된다.
Transformer는 논문 발표 당시 English-to-German newstest2014과 English-to-French newstest2014 데이터에서 SOTA(state-of-the-art)를 달성하였다.
Transformer 이후 BERT, GPT 등의 모델이 등장하기 시작했다.
Reference
- https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
- 1) 트랜스포머(Transformer) - 딥 러닝을 이용한 자연어 처리 입문
- 1) 어텐션 메커니즘 (Attention Mechanism) - 딥 러닝을 이용한 자연어 처리 입문
- https://blog.pingpong.us/transformer-review/
- Transformer는 이렇게 말했다, "Attention is all you need."
- Transformer 정리
- [딥러닝 기계 번역] Transformer: Attention Is All You Need (꼼꼼한 딥러닝 논문 리뷰와 코드 실습) - YouTube
'Study' 카테고리의 다른 글
| Passage Retrieval 관련 연구 (0) | 2022.01.22 |
|---|---|
| [논문] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (0) | 2022.01.22 |
| 추천 시스템 성능 평가 지표(Precision@k, Recall@k, Hit@k, MAP, MRR, nDCG) (0) | 2022.01.09 |
| 회귀 모델 성능 평가 지표(MAE, MSE, RMSE, MAPE 등) (1) | 2022.01.07 |
| 분류 모델 성능 평가 지표(Accuracy, Precision, Recall, F1 score 등) (2) | 2022.01.02 |
